|
I am a master student at Institute of Automation in Beijing, where I work on video multi-modal understanding and time series mining. I did my undergraduate degree at UESTC and I am doing my Master's Degree at Institute of Automation, where I am advised by Gaofeng Meng. Email / CV / Bio / Google Scholar / Github |

|
|
I'm interested in multi-modal video understanding, continual learning, and time series mining. Much of my research is about mutli-modal learning (visual, text, speech, etc) from videos. Representative papers are highlighted. |
|
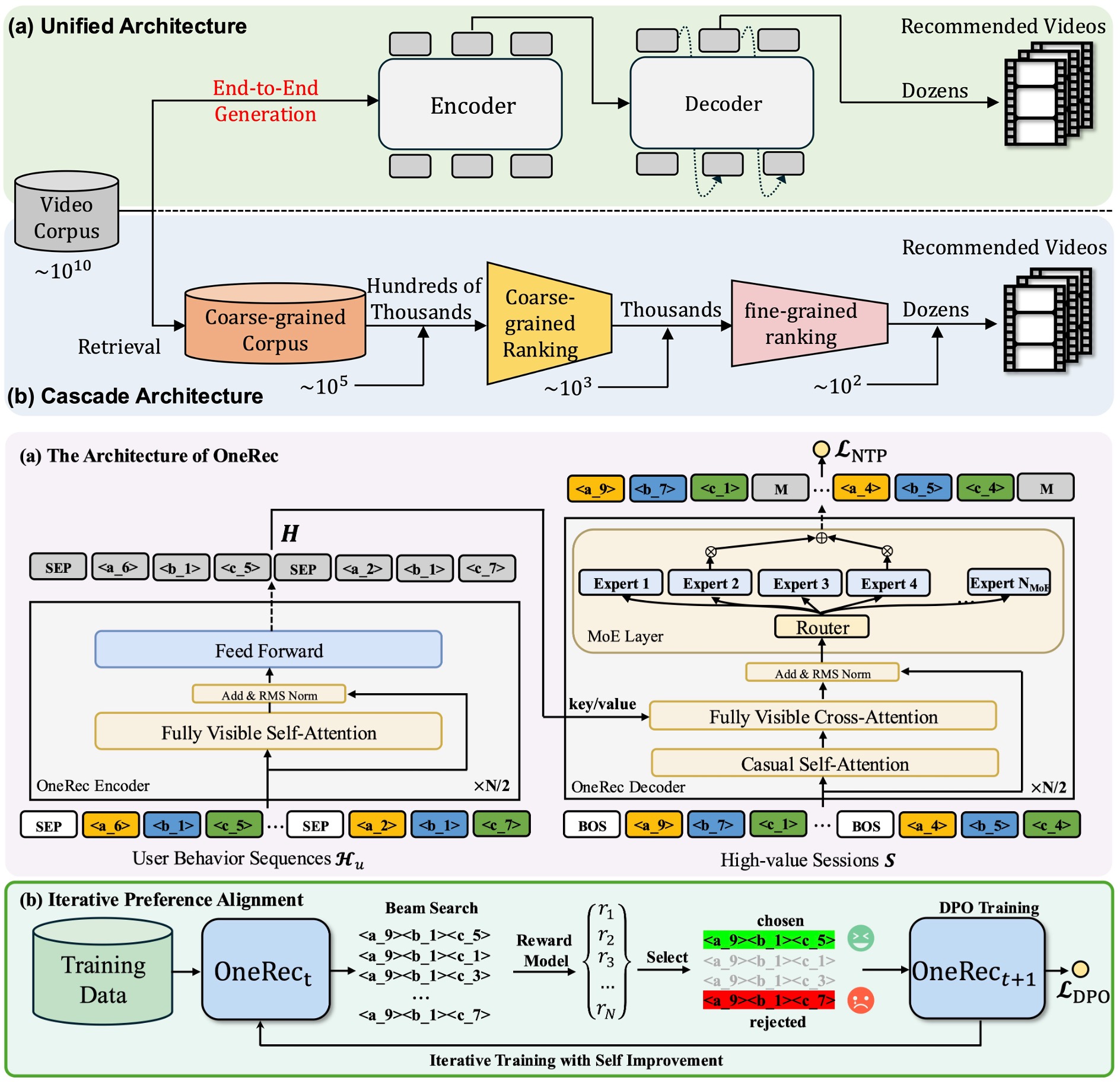
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, Guorui Zhou* Submitted to KDD'25 paper / Workshop-WWW'25 / video Recently, generative retrieval-based recommendation systems (GRs) have emerged as a promising paradigm by directly generating candidate videos in an autoregressive manner. However, most modern recommender systems adopt a retrieve-and-rank strategy, where the generative model functions only as a selector during the retrieval stage. In this paper, we propose OneRec, which replaces the cascaded learning framework with a unified generative model. To the best of our knowledge, this is the first end-to-end generative model that significantly surpasses current complex and well-designed recommender systems in real-world scenarios. Specifically, OneRec includes an encoder-decoder structure, a session-wise generation approach and an Iterative Preference Alignment module combined with Direct Preference Optimization (DPO) to enhance the quality of the generated results. We deployed OneRec in the main scene of Kuaishou, a short video recommendation platform with hundreds of millions of daily active users, achieving a 1.6% increase in watch-time. |
|
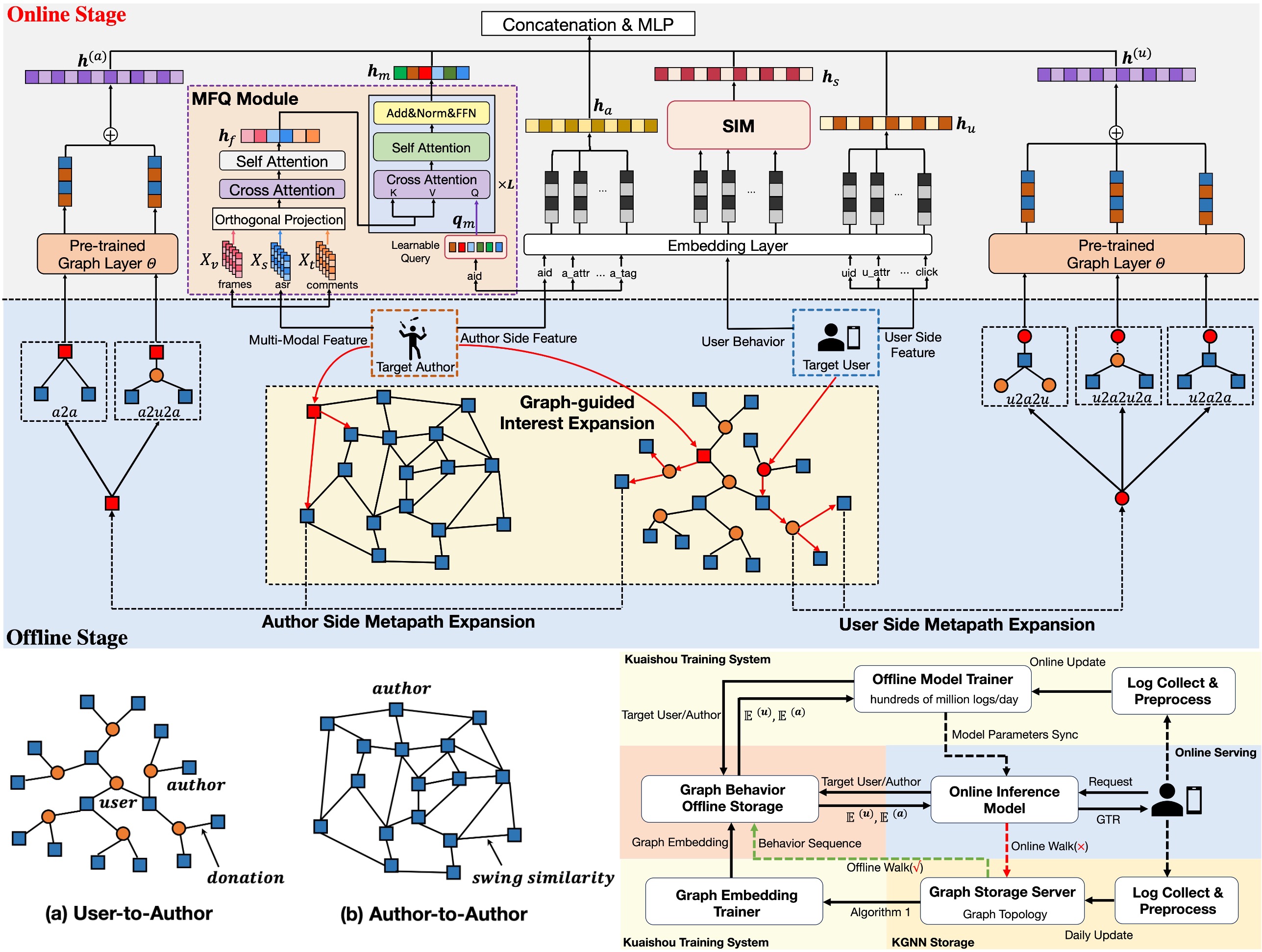
Jiaxin Deng, Shiyao Wang, Yuchen Wang, Jiansong Qi, Liqin Zhao, Guorui Zhou*, Gaofeng Meng KDD, 2024 (Oral Presentation) paper / slides / video / poster Live streaming services are becoming increasingly popular due to real-time interactions and entertainment. Accurately modeling the gifting interaction not only enhances users' experience but also increases streamers' revenue. In this work, we propose MMBee based on real-time Multi-Modal Fusion and Behaviour Expansion to address these issues. Specifically, we first present a Multi-modal Fusion Module with Learnable Query (MFQ) to perceive the dynamic content of streaming segments and process complex multi-modal interactions, including images, text comments and speech. To alleviate the sparsity issue of gifting behaviors, we present a novel Graph-guided Interest Expansion (GIE) approach that learns both user and streamer representations on large-scale gifting graphs with multi-modal attributes. It consists of two main parts: graph node representations pre-training and metapath-based behavior expansion, all of which help model jump out of the specific historical gifting behaviors for exploration and largely enrich the behavior representations. |
|
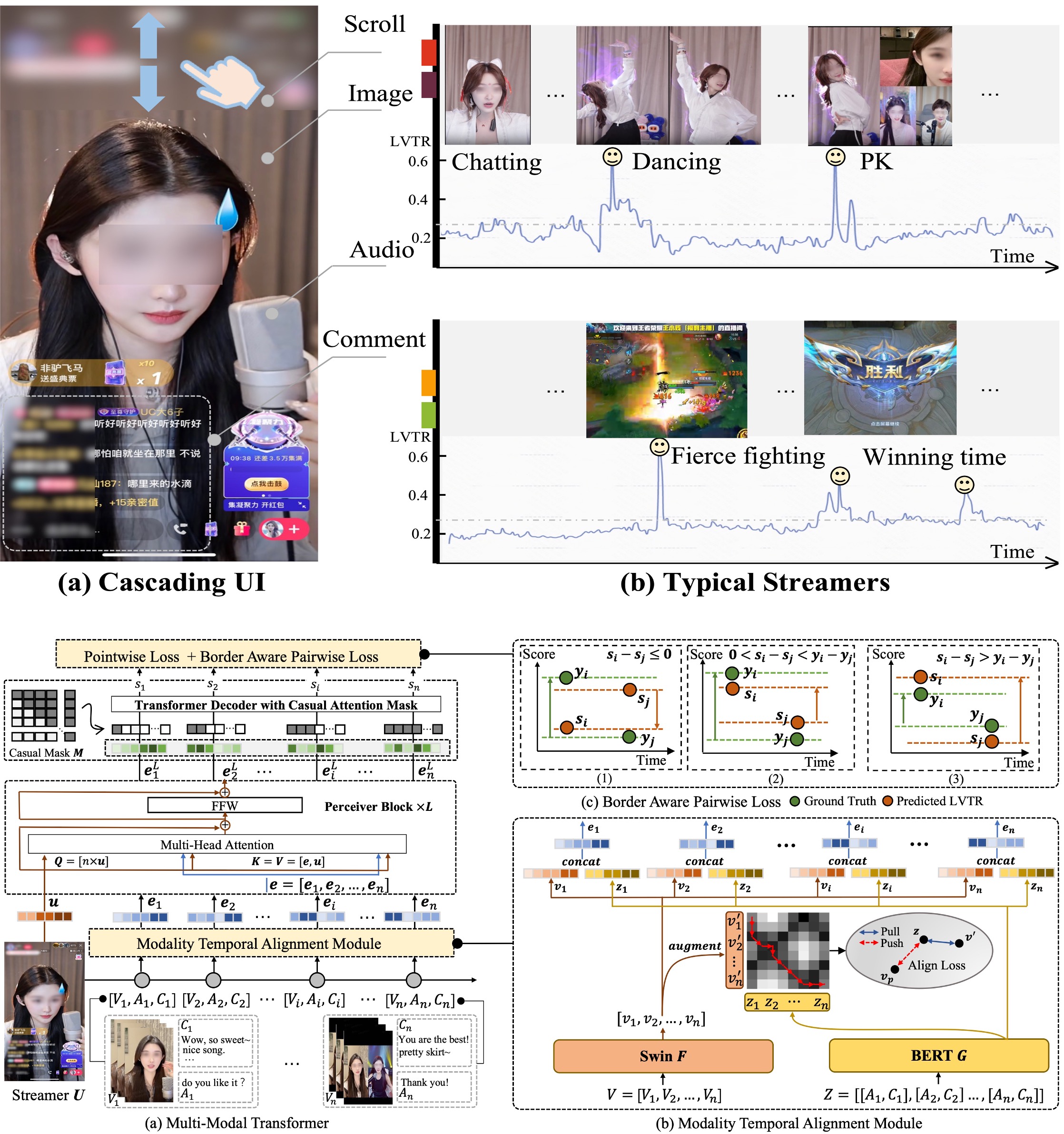
Jiaxin Deng, Shiyao Wang, Dong Shen, Liqin Zhao, Fan Yang, Guorui Zhou, Gaofeng Meng* ICME, 2024 (Poster) paper / poster / KLive dataset Recently, live streaming platforms have gained immense popularity. Traditional video highlight detection mainly focuses on visual features and utilizes both past and future content for prediction. However, live streaming requires models to infer without future frames and process complex multimodal interactions, including images, audio and text comments. To address these issues, we propose a multimodal transformer that incorporates historical look-back windows. We introduce a novel Modality Temporal Alignment Module to handle the temporal shift of cross-modal signals. Additionally, using existing datasets with limited manual annotations is insufficient for live streaming whose topics are constantly updated and changed. Therefore, we propose a novel Border-aware Pairwise Loss to learn from a large-scale dataset and utilize user implicit feedback as a weak supervision signal. Extensive experiments show our model outperforms various strong baselines on both real-world scenarios and public datasets. |
|
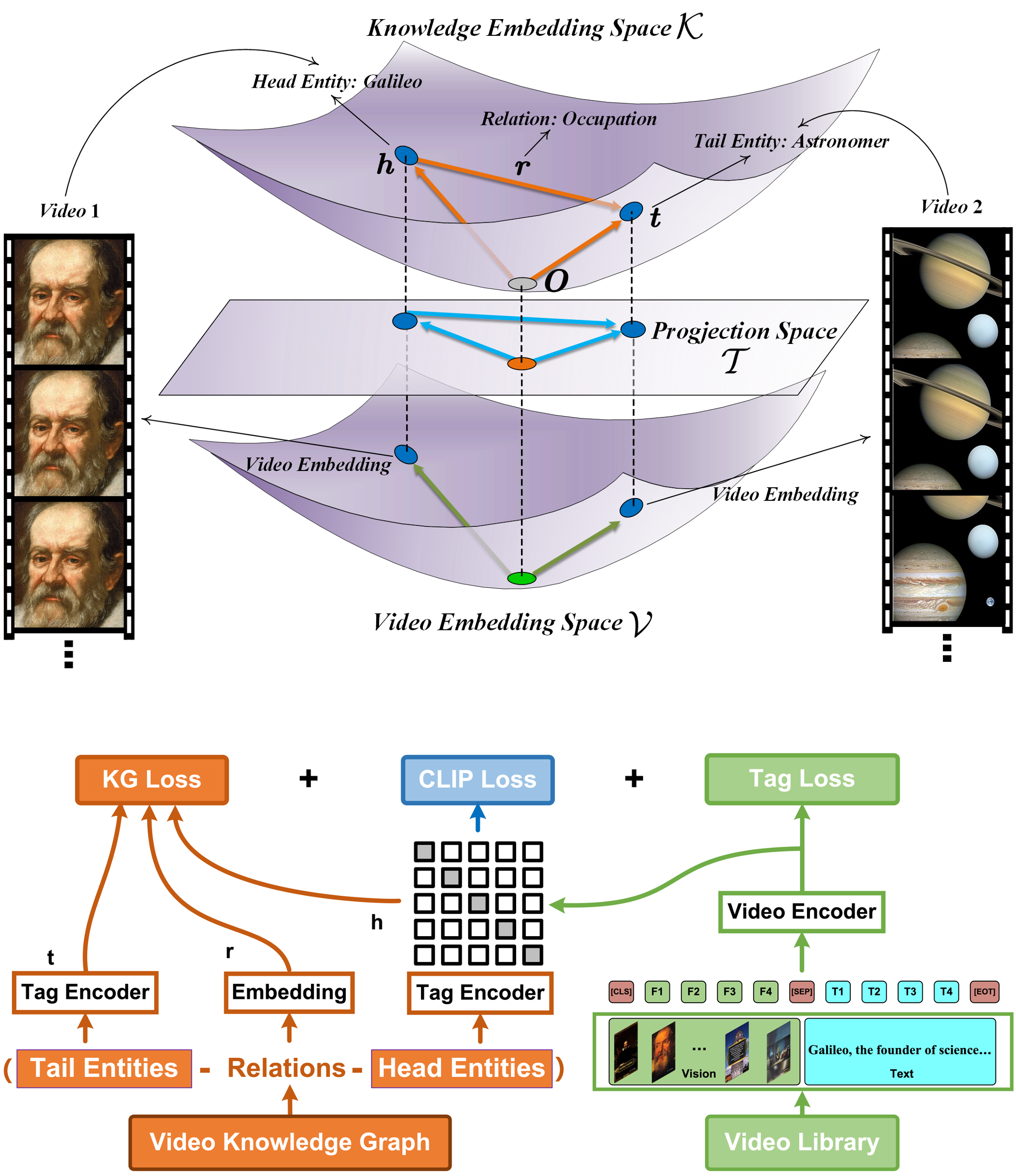
Jiaxin Deng, Dong Shen, Haojie Pan, Xiangyu Wu, Ximan Liu, Gaofeng Meng*, Fan Yang, Tingting Gao, Ruiji Fu, Zhongyuan Wang ICMR, 2023 (Oral Presentation, Best Paper Award Candidate) paper / slides / video We propose a heterogeneous dataset that contains the multi-modal video entity and fruitful common sense relations. This dataset also provides multiple novel video inference tasks like the Video-Relation-Tag (VRT) and Video-Relation-Video (VRV) tasks. Furthermore, based on this dataset, we propose an end-to-end model that jointly optimizes the video understanding objective with knowledge graph embedding, which can not only better inject factual knowledge into video understanding but also generate effective multi-modal entity embedding for KG. |